

Here I wish to display some examples of visually weighted regression diagnostics in SPSS, along with some discussion about the goals and relationship to the greater visualization literature I feel is currently missing from the disscussion. To start, the current label of “visually weighted regression” can be attributed to Solomon Hsiang. Below are some of the related discussions (on both Solomon’s and Andrew Gelman’s blog), and a paper Solomon has currently posted on SSRN.
- Fight Entropy: Visually-Weighted Regression
- Hsiang (2012) SSRN paper.
- Stat. Modeling, Causal Inf., and Social Science: Visually weighting regression displays
- Stat. Modeling, Causal Inf., and Social Science: Graphs showing uncertainty using lighter intensities for the lines that go further from the center, to de-emphasize the edges
- Stat. Modeling, Causal Inf., and Social Science: Graphs showing regression uncertainty: the code!
- Fight Entropy: Watercolor regression
- Stat. Modeling, Causal Inf., and Social Science: Watercolor regression
- Fight Entropy: Visually-weighted confidence intervals
Also note that Felix Schonbrodt has provided example implementations in R. Also the last link is an example from the is.R() blog.
- Schonbrodt: Visually weighted regression in R (a la Solomon Hsiang)
- Schonbrodt: Amazing fMRI plots for everybody!
- Schonbrodt: Visually weighted/ Watercolor Plots, new variants: Please vote!
- is.R: Simple visually-weighted regression plots
Hopefully that is near everyone (and I have not left out any discussion!)
A rundown of their motivation (although I encourage everyone to either read Solomon’s paper or the blog posts), is that regression estimates have a certain level of uncertainty. Particularly at the ends of the sample space of the independent variable observations, and especially for non-linear regression estimates, the uncertainty tends to be much greater than where we have more sample observations. The point of visually weighted regression is to deemphasize area of the plot where our uncertainty about the predicted values is greatest. This conversely draws ones eye to the area of the plot where the estimate is most certain.
I’ll discuss the grammar of these graphs a little bit, and from there it should be clear how to implement them in whatever software (as long as it supports transparency and fitting the necessary regression equations!). So even though I’m unaware of any current SAS (or whatever) examples, I’m sure they can be done.
SPSS Implementation
First lets just generate some fake data in SPSS, fit a predicted regression line, and plot the intervals using lines.
*******************************.
set seed = 10. /* sets random seed generator to make exact data reproducible */.
input program.
loop #j = 1 to 100. /*I typically use scratch variables (i.e. #var) when making loops.
compute X = RV.NORM(0,1). /*you can use the random number generators to make different types of data.
end case.
end loop.
end file.
end input program.
dataset name sim.
execute. /*note spacing is arbitrary and is intended to make code easier to read.
*******************************.
compute Y = 0.5*X + RV.NORM(0,SQRT(0.5)).
exe.
REGRESSION
/MISSING LISTWISE
/STATISTICS COEFF OUTS R ANOVA
/CRITERIA=PIN(.05) POUT(.10) CIN(95)
/NOORIGIN
/DEPENDENT Y
/METHOD=ENTER X
/SAVE PRED MCIN.
*Can map seperate variable based on size of interval to color and transparency.
compute size = UMCI_1 - LMCI_1.
exe.
formats UMCI_1 LMCI_1 Y X size PRE_1 (F1.0).
*Simple chart with lines.
GGRAPH
/GRAPHDATASET NAME="graphdataset" VARIABLES=X Y PRE_1 LMCI_1 UMCI_1 MISSING=LISTWISE
REPORTMISSING=NO
/GRAPHSPEC SOURCE=INLINE DEFAULTTEMPLATE=yes.
BEGIN GPL
SOURCE: s=userSource(id("graphdataset"))
DATA: X=col(source(s), name("X"))
DATA: Y=col(source(s), name("Y"))
DATA: PRE_1=col(source(s), name("PRE_1"))
DATA: LMCI_1=col(source(s), name("LMCI_1"))
DATA: UMCI_1=col(source(s), name("UMCI_1"))
GUIDE: axis(dim(1), label("X"))
GUIDE: axis(dim(2), label("Y"))
SCALE: linear(dim(1), min(-3.8), max(3.8))
SCALE: linear(dim(2), min(-3), max(3))
ELEMENT: point(position(X*Y), size(size."2"))
ELEMENT: line(position(X*PRE_1), color.interior(color.red))
ELEMENT: line(position(X*LMCI_1), color.interior(color.grey))
ELEMENT: line(position(X*UMCI_1), color.interior(color.grey))
END GPL.
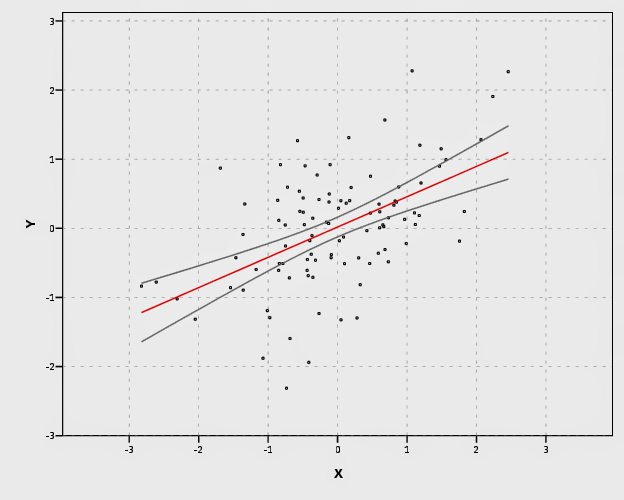
In SPSS’s grammar, it is simple to plot the predicted regression line with areas of the higher confidence interval as more transparent. Here I use saved values from the regression equation, but you can also use functions within GPL (see smooth.linear and region.confi.smooth).
*Using path with transparency between segments.
GGRAPH
/GRAPHDATASET NAME="graphdataset" VARIABLES=X Y PRE_1 size
/GRAPHSPEC SOURCE=INLINE.
BEGIN GPL
SOURCE: s=userSource(id("graphdataset"))
DATA: X=col(source(s), name("X"))
DATA: Y=col(source(s), name("Y"))
DATA: PRE_1=col(source(s), name("PRE_1"))
DATA: size=col(source(s), name("size"))
GUIDE: axis(dim(1), label("X"))
GUIDE: axis(dim(2), label("Y"))
GUIDE: legend(aesthetic(aesthetic.transparency.interior), null())
SCALE: linear(dim(1), min(-3.8), max(3.8))
SCALE: linear(dim(2), min(-3), max(3))
ELEMENT: point(position(X*Y), size(size."2"))
ELEMENT: line(position(X*PRE_1), color.interior(color.red), transparency.interior(size), size(size."4"))
END GPL.
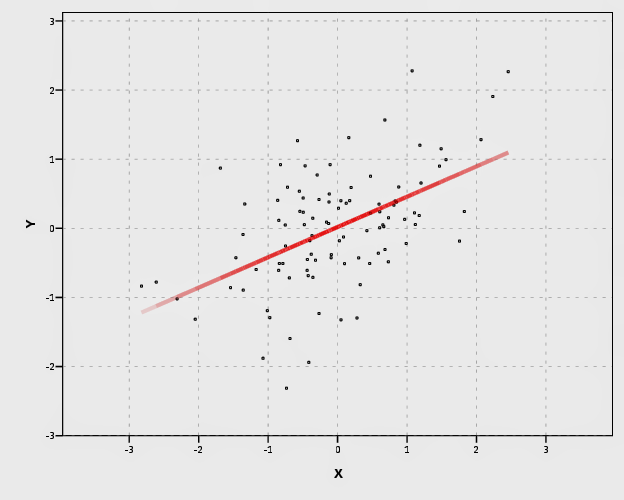
It is a bit harder to make the areas semi-transparent throughout the plot. If you use an area.difference ELEMENT, it makes the entire area a certain amount of transparency. If you use intervals with the current data, the area will be too sparse. So what I do is make new data, sampling more densley along the x axis and make the predictions. From this we can use interval element to plot the predictions, mapping the size of the interval to transparency and color saturation.
*make new cases to have a consistent sampling of x values to make the intervals.
input program.
loop #j = 1 to 500.
compute #min = -5.
compute #max = 5.
compute X = #min + (#j - 1)*(#max - #min)/500.
compute new = 1.
end case.
end loop.
end file.
end input program.
dataset name newcases.
execute.
dataset activate sim.
add files file = *
/file = 'newcases'.
exe.
dataset close newcases.
match files file = *
/drop UMCI_1 LMCI_1 PRE_1.
REGRESSION
/MISSING LISTWISE
/STATISTICS COEFF OUTS R ANOVA
/CRITERIA=PIN(.05) POUT(.10) CIN(95)
/NOORIGIN
/DEPENDENT Y
/METHOD=ENTER X
/SAVE PRED MCIN.
compute size = UMCI_1 - LMCI_1.
formats ALL (F1.0).
temporary.
select if new = 1.
GGRAPH
/GRAPHDATASET NAME="graphdataset" VARIABLES=X PRE_1 LMCI_1 UMCI_1 size MISSING=LISTWISE
REPORTMISSING=NO
/GRAPHSPEC SOURCE=INLINE.
BEGIN GPL
SOURCE: s=userSource(id("graphdataset"))
DATA: X=col(source(s), name("X"))
DATA: PRE_1=col(source(s), name("PRE_1"))
DATA: LMCI_1=col(source(s), name("LMCI_1"))
DATA: UMCI_1=col(source(s), name("UMCI_1"))
DATA: size=col(source(s), name("size"))
TRANS: sizen = eval(size*-1)
TRANS: sizer = eval(size*.01)
GUIDE: axis(dim(1), label("X"))
GUIDE: axis(dim(2), label("Y"))
GUIDE: legend(aesthetic(aesthetic.transparency.interior), null())
GUIDE: legend(aesthetic(aesthetic.transparency.exterior), null())
GUIDE: legend(aesthetic(aesthetic.color.saturation.exterior), null())
SCALE: linear(aesthetic(aesthetic.transparency), aestheticMinimum(transparency."0.90"), aestheticMaximum(transparency."1"))
SCALE: linear(aesthetic(aesthetic.color.saturation), aestheticMinimum(color.saturation."0"),
aestheticMaximum(color.saturation."0.01"))
SCALE: linear(dim(1), min(-5.5), max(5))
SCALE: linear(dim(2), min(-3), max(3))
ELEMENT: interval(position(region.spread.range(X*(LMCI_1 + UMCI_1))), transparency.exterior(size), color.exterior(color.red), size(size."0.005"),
color.saturation.exterior(sizen))
ELEMENT: line(position(X*PRE_1), color.interior(color.darkred), transparency.interior(sizer), size(size."5"))
END GPL.
exe.
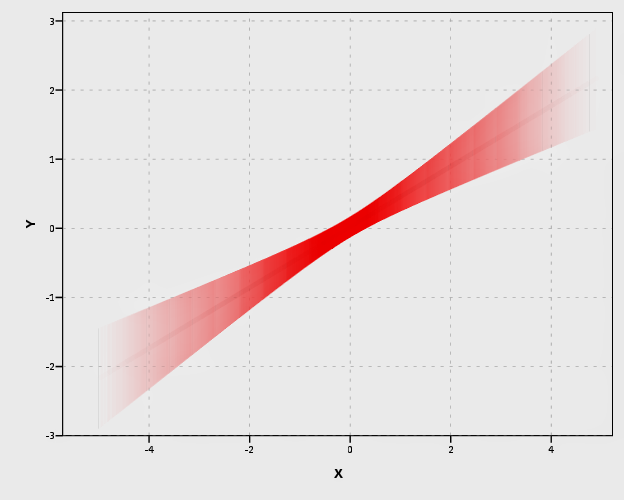
Unfortunately, this creates some banding effects. Sampling fewer points makes the banding effects worse, and sampling more reduces the ability to make the plot transparent (and it is still produces banding effects). So, to produce one that looks this nice took some experimentation with how densely the new points were sampled, how aesthetics were mapped, and how wide the interval lines would be.
I tried to map a size aesthetic to the line and it works ok, you can still see some banding effects. Also note, to get the size of the line to be vertical (as oppossed to oriented in whatever direction the line is orientated) one needs to use a step line function. The jump() specification makes it so the vertical lines in the step chart aren’t visible. It took some trial and error to map the size to the exact interval (not sure if one can use the percent specifications to fix that trial and error). The syntax for lines though generalizes to multiple groups in SPSS easier than does the interval elements (although Solomon comments on one of Felix’s blog post that he prefers the non-interval plots with multiple groups, due to drawing difficulties and getting too busy I believe). Also FWIW it took less fussing with the density of the sample points and drawing of transparency to make the line mapped to size look nice.
temporary.
select if new = 1.
GGRAPH
/GRAPHDATASET NAME="graphdataset" VARIABLES=X PRE_1 LMCI_1 UMCI_1 size MISSING=LISTWISE
REPORTMISSING=NO
/GRAPHSPEC SOURCE=INLINE.
BEGIN GPL
SOURCE: s=userSource(id("graphdataset"))
DATA: X=col(source(s), name("X"))
DATA: PRE_1=col(source(s), name("PRE_1"))
DATA: LMCI_1=col(source(s), name("LMCI_1"))
DATA: UMCI_1=col(source(s), name("UMCI_1"))
DATA: size=col(source(s), name("size"))
GUIDE: axis(dim(1), label("X"))
GUIDE: axis(dim(2), label("Y"))
GUIDE: legend(aesthetic(aesthetic.transparency.interior), null())
GUIDE: legend(aesthetic(aesthetic.transparency.exterior), null())
GUIDE: legend(aesthetic(aesthetic.size), null())
SCALE: linear(aesthetic(aesthetic.size), aestheticMinimum(size."0.16in"), aestheticMaximum(size."1.05in"))
SCALE: linear(aesthetic(aesthetic.transparency.interior), aestheticMinimum(transparency."0.5"), aestheticMaximum(transparency."1"))
SCALE: linear(dim(1), min(-5.5), max(5))
SCALE: linear(dim(2), min(-3), max(3))
ELEMENT: line(position(smooth.step.left(X*PRE_1)), jump(), color.interior(color.black), transparency.interior(size), size(size))
ELEMENT: line(position(X*PRE_1), color.interior(color.black), transparency.interior(size), size(size."3"))
END GPL.
exe.
*Add these two lines to see the actual intervals line up (without ending period).
*ELEMENT: line(position(X*LMCI_1), color.interior(color.black)).
*ELEMENT: line(position(X*UMCI_1), color.interior(color.black)).
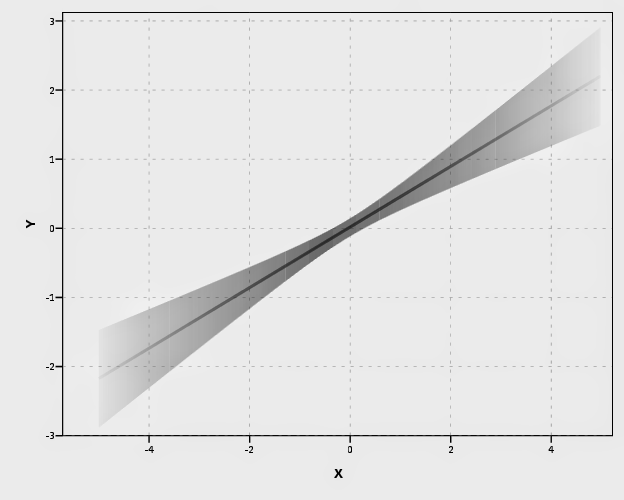
Also note Solomon suggests that the saturation of the plot should be higher towards the mean of the predicted value. I don’t do that here (but have a superimposed predicted line you can see). A way to do that in SPSS would be to make multiple intervals and continually superimpose them (see Maltz and Zawitz (1998) for an applied example of something very similar). Another way may involve using color gradients for the intervals (which isn’t possible through syntax, but is through a chart template). There are other examples that I could do in SPSS (spaghetti plots of bootstrapped estimates, discrete bins for certain intervals) but I don’t provide examples of them for reasons noted below.
I will try to provide some examples of more interesting non-linear graphs in the near future (I recently made a macro to estimate restricted cubic spline bases). But this should be enough for now to show how to implement such plots in SPSS for everyone, and the necessary grammar to make the charts.
Some notes on current discussion and implementations
My main critiques of the current implementations (and really more so the discussion) are more curmudgeonly than substantive, but hopefully it is clear enough to provide some more perspective on the work. I’ll start by saying that, it is unclear if either Solomon or Felix have read the greater visualization literature on visualizing uncertainty. While I can’t fault Felix for that so much (it is a bit much to expect a blog post to have a detailed bibliography) Solomon has at least posted a paper on SSRN. I don’t mean this as too much of a critique to Solomon, he has a good idea, and a good perspective on visualization (if you read his blog he has plenty of nice examples). But, it is more aimed at a particular set of potential alternative plots that Solomon and Felix have presented that I don’t feel are very good ideas.
Like all scientific work, we stand on the shoulders of those who come before us. While I haven’t explicitly seen visually weighted regression plots in any prior work, there are certainly many very similar examples. The most obvious would probably be the discussion of Jackson (2008), and for applied examples of this technique to very similar regression contexts are Maltz and Zawitz (1998) and Esarey and Pierce (2012) (besides Jackson (2008), there is a variety of potential other related literature cited in the discussion to Gelman’s blog posts – but this article is blatently related). There are undoubtedly many more, likely even older than the Maltz paper, and there is a treasure trove of papers about displaying error bars on this Andrew Gelman post. Besides proper attribution, this isn’t just pedantic, we should take the lessons learned from the prior literature and apply them to our current situation. There are large literatures on visualizaing uncertainty, and it is a popular enough topic that it has its own sections in cartography and visualization textbooks (MacEachren 2004; Slocum et al. 2005; Wilkinson 2005).
In particular, there is one lesson I feel should strongly reflect on the current discussion, and that is visualizing crisp lines in graphics implies the exact opposite of uncertainty to the viewers. Spiegelhalter, Pearson, and Short (2011) have an example of this, where a graphic about a tornado warning was taken a bit more to heart than it should have, and instead of people interpreting the areas of highest uncertainty in the predicted path as just that, they interpreted it as more a deterministic. There appears to be good agreement about using alpha blending (Roth, Woodruff, and Johnson 2010), and having fuzzy lines are effective ways of displaying uncertainty (MacEachren 2004; Wood et al. 2012). Thus, we have good evidence that, if the goal of the plot is to deemphasize portions of the regression that have large amounts of uncertainty in the estimates, we should not plot those estimates using discrete cut-offs. This is why I find Felix’s poll results unfortunate, in that the plot with the discrete cut-offs is voted the highest by viewers of the blog post!
So here is an example graph by Felix of the discrete bins (note this is the highest voted image in Felix’s poll!). Again to be clear, discrete bins suggests the exact opposite of uncertainty, and certainly does not deemphasize areas of the plot that have the greatest amount of uncertainty.

Here is the example of the plot from Solomon that also has a similar problem with discrete bins. The colors portray uncertainty, but it is plain to see the lattice on the plot, and I don’t understand why this meets any of Solomon’s original goals. It takes ink to plot the lattice!

More minor, but still enough to guide our implementations, the plots that superimpose multiple bootstrapped estimates, while they are likely ok to visualize uncertainty, the resulting spaghetti make the plots much more complex. The shaded areas maintain a much more condense and clear to understand visual, while superimposing multiple lines on the plot creates a difficult to envision distribution (here I have an example on the CV blog, and it is taken from Carr and Pickle (2009)). It may aid understanding uncertainty about the regression estimate, but it detracts from visualizing any more global trends in the regression estimate. It also fails to meet the intial goal of deemphasizing areas of the plot that are most uncertain. It accomplishes quite the opposite actually, and areas where the bootstrapped estimates have a greater variance will draw more attention because they are more dispersed on the plot.
Here is an example from Solomon’s blog of the spaghetti plots with the lines drawn heavily transparent.

Solomon writes about the spaghetti plot distraction in his SSRN paper, but still presents the examples as if they are reasonable alternatives (which is strange). I would note these would be fine and dandy if visualizing the uncertainty was itself an original goal of the plot, but that isn’t the goal! To a certain extent, displaying an actual interval is countervailing to the notion of deemphasizing that area of the chart. The interval needs to command a greater area of the chart. I think Solomon has some very nice examples where the tradeoff is reasonable, with plotting the areas with larger intervals in lower color saturation (here I use transparency to the same effect). I doubt this is news to Solomon – what he writes in his SSRN paper conforms to what I’m saying as far as I can tell – I’m just confused why he presents some examples as if they are reasonable alternatives. I think it deserves reemphasis though given all the banter and implementations floating around the internet, especially with some of the alternatives Felix has presented.
I’m not sure if Solomon and Felix really appreciate though the distinction between hard lines and soft lines though after reading the blog post(s) and the SSRN paper. Of course these assertions and critiques of mine should be tested in experimental settings, but we should not ignore prior research in spite of a lack of experimental findings. I don’t want these critiques to be viewed too harshly though, and I hope Solomon and Felix take them to heart (either in future implementations or actual papers discussing the technique).
Citations
Carr, Daniel B., and Linda Williams Pickle. 2009. Visualizing Data Patterns with Micromaps. Boca Rotan, FL: CRC Press.
Esarey, Justin, and Andrew Pierce. 2012. Assessing fit quality and testing for misspecification in binary-dependent variable models. Political Analysis 20: 480–500.
Hsiang, Solomon M. 2012. Visually-Weighted Regression.
Jackson, Christopher H. 2008. Displaying uncertainty with shading. The American Statistician 62: 340–47.
MacEachren, Alan M. 2004. How maps work: Representation, visualization, and design. New York, NY: The Guilford Press.
Maltz, Michael D., and Marianne W. Zawitz. 1998. Displaying violent crime trends using estimates from the National Crime Victimization Survey. US Department of Justice, Office of Justice Programs, Bureau of Justice Statistics.
Roth, Robert E., Andrew W. Woodruff, and Zachary F. Johnson. 2010. Value-by-alpha maps: An alternative technique to the cartogram. The Cartographic Journal 47: 130–40.
Slocum, Terry A., Robert B. McMaster, Fritz C. Kessler, and Hugh H. Howard. 2005. Thematic cartography and geographic visualization. Prentice Hall.
Spiegelhalter, David, Mike Pearson, and Ian Short. 2011. Visualizing uncertainty about the future. Science 333: 1393–1400.
Wilkinson, Leland. 2005. The grammar of graphics. New York, NY: Springer.
Wood, Jo, Petra Isenberg, Tobias Isenberg, Jason Dykes, Nadia Boukhelifa, and Aidan Slingsby. 2012. Sketchy Rendering for Information Visualization. Visualization and Computer Graphics, IEEE Transactions on 18: 2749–58.


2 Comments